
缓存是现在几乎所有项目都会用到的技术,起到了对抗高可用高并发的作用。那么缓存在项目中的使用目的、使用场景、使用中要注意的问题有哪些呢?之后的redis系列,会一一阐述这些问题。第一篇文章从最基础的redis的数据类型和 使用场景说起,这篇文章主要描述以下内容:
- Redis 与 Memcached的区别
- Redis 的线程模型
- Redis 的数据类型和使用场景
目录:
一、缓存概述
缓存的使用目的:
用缓存,主要有两个用途:高性能、高并发。下面假设两个场景:
场景一:假设有个操作,一个请求过来,需要进行各种乱七八糟mysql操作 ,查出来的这个结果耗时 600ms。但是这个结果可能接下来几个小时都不会变了,或者变了也可以不用立即反馈给用户。那么此时就可以用缓存来解决性能问题了。可以把这个花了600ms 查出来的结果,扔缓存里,一个 key 对应一个 value,下次再有人查,直接从缓存里,通过一个 key 查出来一个 value,2ms 搞定。性能提升 300 倍。这个场景是redis用来解决服务器性能问题。对于一些需要复杂操作耗时查出来的结果,且确定后面不怎么变化,但是有很多读请求,那么直接将查询出来的结果放在缓存中,后面直接读缓存就好。
场景二:比如某个秒杀请求高峰期一秒钟过来的请求有 1 万,如果用 mysql 支持绝对会死掉,因为mysql是比较重的数据库,mysql 单机支撑到 2000QPS 也开始容易报警了,并不适合高并发场景。你这个时候就只能上缓存,把很多数据放缓存。缓存功能简单,说白了就是 key-value 式操作,而且单机支撑的并发量很高,轻松可以支持一秒几万十几万的并发量。单机承载并发量是 mysql 单机的几十倍。因为缓存是走内存的,内存天然就支撑高并发。
但是在缓存的使用过程中也会有一些问题需要注意,大致分为以下几点:
- 缓存与数据库双写不一致
- 缓存雪崩、缓存穿透、缓存击穿
- 缓存并发竞争
Redis和Memcached的区别:
目前服务器端用作缓存的中间件主流就是Redis,还有一个就是Memcached。但是由于Memcached功能的单一和性能问题,现在的项目已经很少用到Memcached。但是这不妨碍我们通过对比他们的功能来更深入了解用Redis和Memcached作为缓存的内容。他们的主要区别分为以下3点:
Redis 支持复杂的数据结构
Redis 相比 Memcached 来说,拥有更多的数据结构,能支持更丰富的数据操作。如果需要缓存能够支持更复杂的结构和操作, Redis 会是不错的选择。Redis 原生支持集群模式
在 Redis3.x 版本中,便能支持 cluster 模式,而 Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据。性能对比
由于 Redis 只使用单核,而 Memcached 可以使用多核,所以平均每一个核上 Redis 在存储小数据时比 Memcached 性能更高。而在 100k 以上的数据中,Memcached 性能要高于 Redis。虽然 Redis 最近也在存储大数据的性能上进行优化,但是比起 Memcached,还是稍有逊色。Redis为什么性能这么好,主要是他采用 了IO 多路复用机制,下面我们来了解Redis的线程模型
二、Redis的线程模型
Redis 内部使用文件事件处理器 file event handler ,这个文件事件处理器是单线程的,所以 Redis 才叫做单线程的模型。但是在面试的时候不能说redis就是单线程的,因为 Redis 6.0 之后的版本抛弃了单线程模型这一设计,原本使用单线程运行的 Redis 也开始选择性地使用多线程模型。它采用 IO 多路复用机制同时监听多个 socket,将产生事件的 socket 压入内存队列中,事件分派器根据 socket 上的事件类型来选择对应的事件处理器进行处理。
多个 socket 可能会并发产生不同的操作,每个操作对应不同的文件事件,但是 IO 多路复用程序会监听多个 socket,会将产生事件的 socket 放入队列中排队,事件分派器每次从队列中取出一个 socket,根据 socket 的事件类型交给对应的事件处理器进行处理。我们通过一张图来了解redis的线程模型:
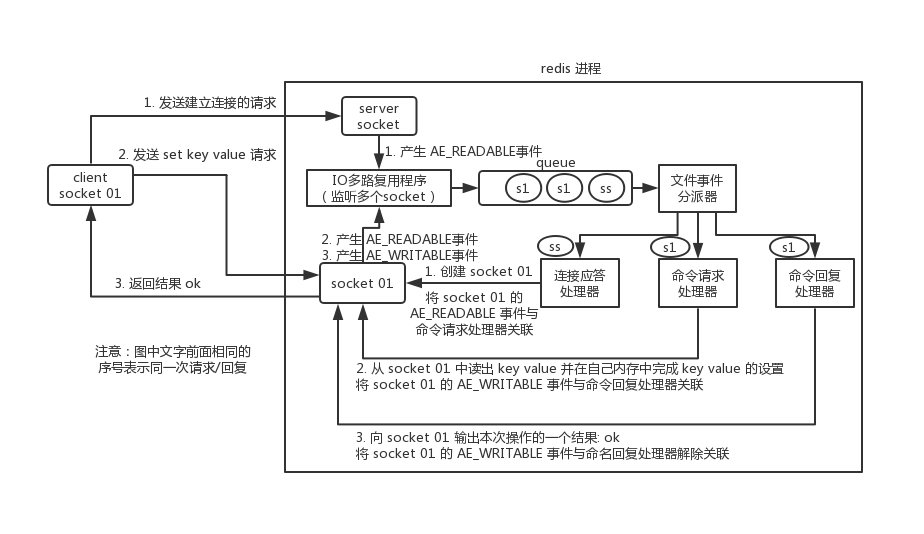
首先需要明白的是,redis的通信是通过 socket 来完成的,不懂的同学可以先去看一看 socket 网络编程。推荐一篇博客:
https://www.cnblogs.com/clschao/articles/9593164.html
文件事件处理器的结构包含 4 个部分:
多个 socket
IO 多路复用程序
文件事件分派器
事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
一个Redis的完整通信为:
1.首先,Redis 服务端进程初始化的时候,会将 server socket 的 AE_READABLE 事件与连接应答处理器关联。
客户端 socket01 向 Redis 进程的 server socket 请求建立连接,此时 server socket 会产生一个 AE_READABLE 事件,IO 多路复用程序监听到 server socket 产生的事件后,将该 socket 压入队列中。文件事件分派器从队列中获取 socket,交给连接应答处理器。连接应答处理器会创建一个能与客户端通信的 socket01,并将该 socket01 的 AE_READABLE 事件与命令请求处理器关联。
2.假设此时客户端发送了一个 set key value 请求,此时 Redis 中的 socket01 会产生 AE_READABLE 事件,IO 多路复用程序将 socket01 压入队列,此时事件分派器从队列中获取到 socket01 产生的 AE_READABLE 事件,由于前面 socket01 的 AE_READABLE 事件已经与命令请求处理器关联,因此事件分派器将事件交给命令请求处理器来处理。命令请求处理器读取 socket01 的 key value 并在自己内存中完成 key value 的设置。操作完成后,它会将 socket01 的 AE_WRITABLE 事件与命令回复处理器关联。
3.如果此时客户端准备好接收返回结果了,那么 Redis 中的 socket01 会产生一个 AE_WRITABLE 事件,同样压入队列中,事件分派器找到相关联的命令回复处理器,由命令回复处理器对 socket01 输入本次操作的一个结果,比如 ok ,之后解除 socket01 的 AE_WRITABLE 事件与命令回复处理器的关联。
这样便完成了一次通信。
这里说的是单线程的模型,那么Redis6.0之后新增的多线程模型,又是指的添加了什么呢?
Redis 的多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程。 之所以这么设计是不想 Redis 因为多线程而变得复杂,需要去控制 key、lua、事务、LPUSH/LPOP 等等的并发问题。
这其实说明 Redis 在有些方面,单线程已经不具有优势了。因为读写网络的 Read/Write 系统调用在 Redis 执行期间占用了大部分 CPU 时间,如果把网络读写做成多线程的方式对性能会有很大提升。
Redis单线程模型效率高的原因:
- 纯内存操作。
- 核心是基于非阻塞的 IO 多路复用机制。
- C 语言实现,一般来说,C 语言实现的程序“距离”操作系统更近,执行速度相对会更快。
- 单线程反而避免了多线程的频繁上下文切换问题,预防了多线程可能产生的竞争问题。
三、Redis支持的数据结构和使用场景
Redis 主要有以下几种数据类型:
- Strings
- Hashes
- Lists
- Sets
- Sorted Sets
Redis 除了这 5 种数据类型之外,还有 Bitmaps、HyperLogLogs、Streams 等。
Strings
这是最简单的类型,就是普通的 set 和 get,做简单的 KV 缓存。
主要命令:set key value
Hashes
这个是类似 map 的一种结构,这个一般就是可以将结构化的数据,比如一个对象(前提是这个对象没嵌套其他的对象)给缓存在 Redis 里,然后每次读写缓存的时候,可以就操作 hash 里的某个字段。
1 | 以一个person对象为例: |
Lists
Lists 是有序列表,这个可以实现的功能就比较多了。
比如可以通过 list 存储一些列表型的数据结构,类似粉丝列表、文章的评论列表之类的东西。
比如可以通过 lrange 命令,读取某个闭区间内的元素,可以基于 list 实现分页查询,这个是很棒的一个功能,基于 Redis 实现简单的高性能分页,可以做类似微博那种下拉不断分页的东西,性能高,就一页一页走。
1 | # 0开始位置,-1结束位置,结束位置为-1时,表示列表的最后一个位置,即查看所有。 |
比如可以搞个简单的消息队列,从 list 头部放进去,从 list 尾巴那里弄出来。
1 | lpush mylist 1 |
Sets
Sets 是无序集合,自动去重。
直接基于 set 将系统里需要去重的数据扔进去,自动就给去重了,如果你需要对一些数据进行快速的全局去重,你当然也可以基于 jvm 内存里的 HashSet 进行去重,但是如果你的某个系统部署在多台机器上呢?得基于 Redis 进行全局的 set 去重。
可以基于 set 玩儿交集、并集、差集的操作,比如交集吧,可以把两个人的粉丝列表整一个交集,找出俩人的共同好友。
1 | # 主要命令: |
Sorted Sets
Sorted Sets 是排序的 set,去重但可以排序,写进去的时候给一个分数,自动根据分数排序。
1 | zadd board 85 zhangsan |