
我们在介绍Collection的时候对Set的了解是:存无序、唯一不可重复的元素的 Collection。通过这篇文章我们来详细理解Set接口以及实现类,通过这篇文章,我们可以了解到以下几点:
- Map接口概要和主要(特有)方法
- Map相关主要实现类主要功能、使用场景以及源码实现
- JDK1.7和1.8的HashMap有何不同
- HashMap面试题推荐
一、Map概要
官方描述:
1 | /** |
从官方描述我们可以对map的作用做出如下归纳:
- Map与Collection在集合框架中属并列存在
- Map存储的是键值对,其中不能包含重复的键,值可以重复;每个键只能对应一个值。
- 元素的存取顺序不能保证一致。由于要保证键的唯一、不重复,需要重写键的hashCode()方法、equals()方法。
- Map集合中键要保证唯一性
- Map存储元素使用put方法,Collection使用add方法
- 也就是Collection是单列集合, Map 是双列集合
- Map集合没有直接取出元素的方法,而是先转成Set集合,在通过迭代获取元素
除了对map的定义做出理解外,java中自带了各种map,总的可以归为三类:
通用map:
也就是java.util包中的map,用于在应用程序中管理映射,包括HashMap、Hashtable、Properties、LinkedHashMap、IdentityHashMap、TreeMap、WeakHashMap、ConcurrentHashMap
专用map:
通常我们不必亲自创建此类Map,而是通过某些其他类对其进行访问 java.util.jar.Attributes、javax.print.attribute.standard.PrinterStateReasons、java.security.Provider、java.awt.RenderingHints、javax.swing.UIDefaults
自行实现map:
一个用于帮助我们实现自己的Map类的抽象类 AbstractMap
map的主要方法有:
1 | /** 添加 */ |
遍历Map的方式(3种):
1.使用keySet
1 | // 第一种方式: 使用keySet |
2.Map.Entry
1 | //通过Map中的entrySet()方法获取存放Map.Entry<K,V>对象的Set集合。 |
1 | // 返回的Map.Entry对象的Set集合 Map.Entry包含了key和value对象 |
3.Stream
1 | map.forEach((k,v) -> System.out.println(k+":"+v)); |
Map继承和实现关系:
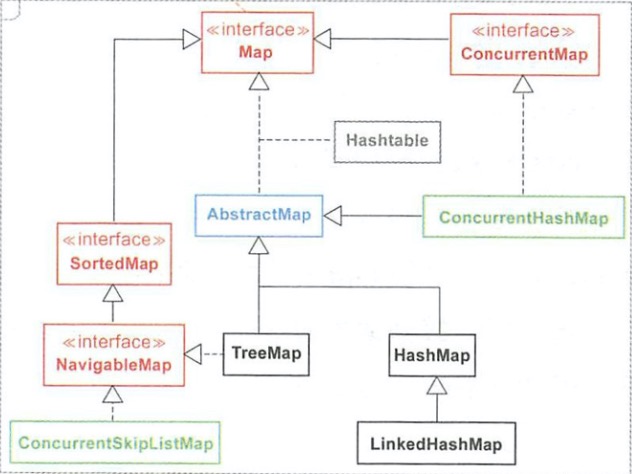
Map的结构关系如上,总结关系List类似,其中最重要的两个实现类为:HashMap、TreeMap和LinkedHashMap。 线程安全的有ConcurrentHashMap。
二、Map主要实现类讲解
HashMap
结构:数组+链表+红黑树
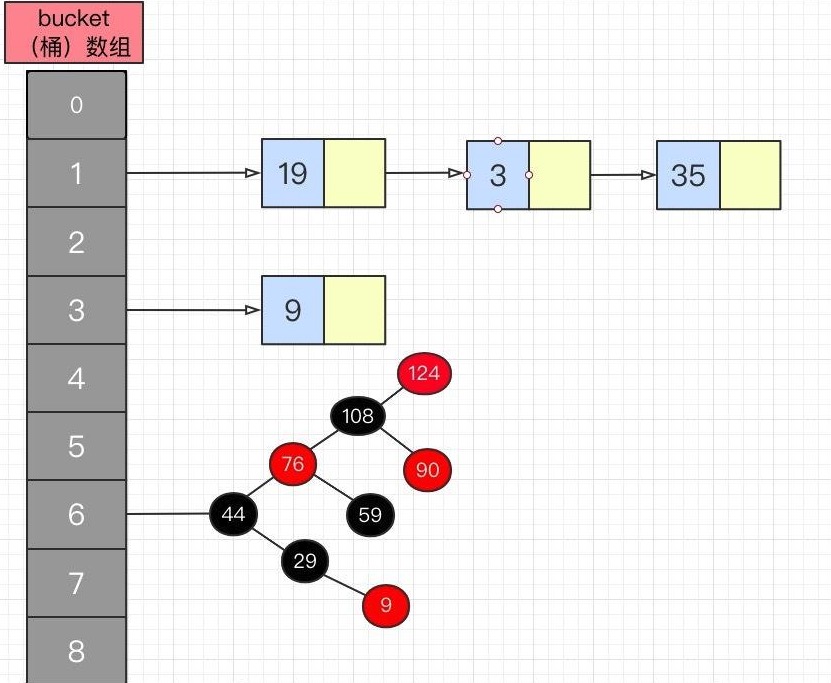
原理概述:基于hashing算法,通过put(k,v)存储对象到HashMap中,通过get(k)方式获取对象。当使用put(k,v)传
递key、value的时候,首先调用hashCode()方法,计算,bucket位置来存储Node对象。
源码:
1 | /** |
默认容量大小为16,加载因子为0.75,主要原因是这两个常量的值都是经过大量的计算和统计得出来的最优解。
1 | /**常用内部类介绍*/ |
1 | /** |
一般情况下都是通过这三种构造方法来初始化 HashMap 的。通过默认的无参构造方法初始化后 HashMap 的容量
就是默认的16,加载因子也是默认的0.75;通过带参数的构造方法可以初始化一个自定义容量和加载因子的
HashMap。通常情况下,加载因子使用默认的0.75就好。
为什么hashMap的容量是2的N次幂?
值得注意的是,HashMap的容量必须要求是2的N次幂,这样可以提高散列的均匀性,降低 Hash 冲突的风险。
但是容量可以通过构造方法传入的,如果我传入一个非2次幂的数进去呢?比如3?也是可以的并且不会报错的,
那是因为 HashMap 自己将这个数转成了一个最接近它的2次幂的数。这个转换的方法是 tableSizeFor(int cap) 。
什么是加载因子?
加载因子和 HashMap 的扩容机制有着非常重要的联系,它可以决定在什么时候才进行扩容。HashMap 是通过
一个阀值来确定是否扩容,当容量超过这个阀值的时候就会进行扩容,而加载因子正是参与计算阀值的一个重要属
性,阀值的计算公式是 容量 * 加载因子。如果通过默认构造方法创建 HashMap ,则阀值为 16 * 0.75 = 12 ,
就是说当 HashMap 的容量超过12的时候就会进行扩容。
put方法
1 | public V put(K key, V value) { |
resize()
扩容会伴随着一次重新hash分配,并且会遍历hash表中所有的元素,非常耗时,因此需要尽量避免rehash。
1 | final Node<K,V>[] resize() { |
1 | // hash值与旧的长度做与运算用于判断元素的在数组中的位置是否需要移动 |
对key求Hash值,计算下标。
如果没有碰撞存入桶中,碰撞则放入bucket的链表或者红黑树中。
如果链表超过阈值(默认链表数超过8,总Entry数超过64)则转换为红黑树,链表长度<6则转换回链表。
key结点存在则替换旧值。
如果桶满(容量*加载因子),就要resize(扩容2倍后重排)。
get()
1 | public V get(Object key) { |
首先将 key hash 之后取得所定位的桶。
如果桶为空则直接返回 null 。
否则判断桶的第一个位置(有可能是链表、红黑树)的 key 是否为查询的 key,是就直接返回 value。
如果第一个不匹配,则判断它的下一个是红黑树还是链表。
红黑树就按照树的查找方式返回值。
不然就按照链表的方式遍历匹配返回值。
LinkedHashMap
原理:LinkedHashMap的实现就是HashMap+LinkedList的实现方式,以HashMap维护数据结构,以LinkList的方式维护数据插入顺序。LinkedHashMap通过维护一个运行所有条目的双向链表,LinkedHashMap保证了元素的迭代顺序。迭代顺序可以是插入顺序或者是访问顺序。
保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的.在遍历的时候会比HashMap慢。key和value均允许为空,非同步的。
TreeMap
能够把它保存的记录根据键(key)排序,默认是按升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。TreeMap不允许key的值为null。非同步的。
HashTable
与 HashMap类似,不同的是:key和value的值均不允许为null;它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢。
ConcurrentHashMap
HashTable 使用一把锁(锁住整个链表结构)处理并发问题,多个线程竞争一把锁,容易阻塞;
ConcurrentHashMap
- JDK 1.7 中使用分段锁(ReentrantLock + Segment + HashEntry),相当于把一个 HashMap 分成多个段,每段分配一把锁,这样支持多线程访问。锁粒度:基于 Segment,包含多个 HashEntry。
- JDK 1.8 中使用 CAS + synchronized + Node + 红黑树。锁粒度:Node(首结点)(实现 Map.Entry)。锁粒度降低了。
三、HashMap在JDK1.7和1.8的不同点
最重要的一点是底层结构不一样,1.7是数组+链表,1.8则是数组+链表+红黑树结构;
jdk1.7中当哈希表为空时,会先调用inflateTable()初始化一个数组;而1.8则是直接调用resize()扩容;
插入键值对的put方法的区别,1.8中会将节点插入到链表尾部,而1.7中是采用头插;
扩容时1.8会保持原链表的顺序,而1.7会颠倒链表的顺序;而且1.8是在元素插入后检测是否需要扩容,1.7则
是在元素插入前;
jdk1.8是扩容时通过hash&cap==0将链表分散,无需改变hash值,而1.7是通过更新hashSeed来修改hash值
达到分散的目的;
扩容策略:1.7中是只要不小于阈值就直接扩容2倍;而1.8的扩容策略会更优化,当数组容量未达到64时,以2
倍进行扩容,超过64之后若桶中元素个数不小于7就将链表转换为红黑树,但如果红黑树中的元素个数小于6
就会还原为链表,当红黑树中元素不小于32的时候才会再次扩容。
jdk1.7中的hash函数对哈希值的计算直接使用key的hashCode值,而1.8中则是采用key的hashCode异或上
key的hashCode进行无符号右移16位的结果,避免了只靠低位数据来计算哈希时导致的冲突,计算结果由高
低位结合决定,使元素分布更均匀;
四、HashMap面试题推荐
HashMap 面试 21 问,这次要跪了!-> https://blog.csdn.net/youanyyou/article/details/105721333
Java集合必会14问(精选面试题整理)-> https://www.jianshu.com/p/939b8a672070
Java集合面试题 -> https://blog.csdn.net/a303549861/article/details/93619042