
上一篇文章概要介绍Collection之后,我们对List的了解是:List是存有序(插入顺序)、允许存相同元素的 Collection。能够精确控制每个元素的插入位置,通过索引(元素在List中位置,类似于数组的下标)来访问List中的元素。通过这篇文章我们来详细回顾List接口以及实现类,我们可以了解到以下几点:
List接口概要和主要(特有)方法
ArrayList, LinkedList和Vector主要功能、使用场景以及源码实现
多线程并发情况下如何使用List
List使用坑点
目录:
一、List概要
官方描述:
首先我们还是来看下JDK1.8对List的官方描述:
1 | /** |
上面的描述阐述了List和Set的区别。List允许存储项的值为空,也允许存储相等值的存储项,还举了e1.equal(e2)的例子。List是除了继承Collection接口中通用的方法以外,还扩展了部分只属于List的方法。List增加了方法是add(int,Object)和addAll(int,Collection),他们的作用是可以在指定的下标处插入元素。
List继承和实现关系:
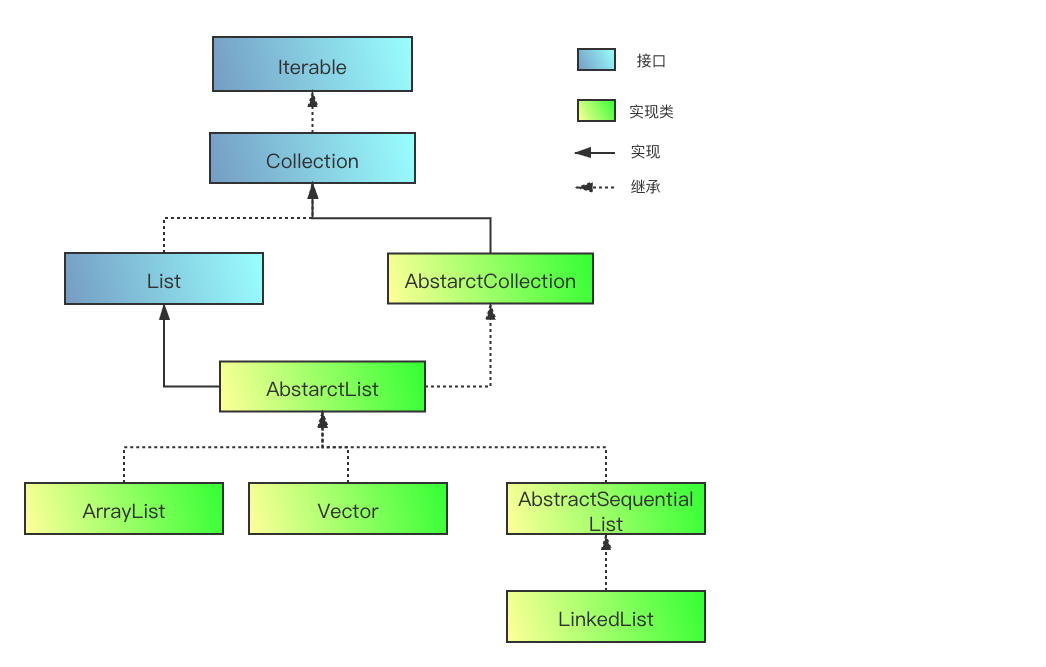
从上图可以看出,List最主要的实现类ArrayList和LinkedList分别继承于AbstarList和AbstractSequentialList。
AbstractList也只是实现了List接口部分的方法,和AbstractCollection是一个思路,遵循接口隔离原则(无须给客户
端暴露不需要的方法)。而AbstractSequentialList是为实现序列访问的数据接口提供的最小化接口实现,可以理解
成他是一个顺序相连的list。
二、List主要实现类讲解
List实现类中我们常用的实现类有 ArrayList、Vector和LinkedList。下面我们来分别分析对应实现类:
ArrayList:
概述:(来自官方文档描述)
1. ArrayList实现了List接口,是顺序容器,即元素存放的数据与放进去的顺序相同,允许放入null元素,底层通
过数组实现。准确的说,是动态数组,和java中的数组相比,他的容量是能动态增长的。除该类未实现同步外,其
余跟Vector大致相同。这里注意的是:为追求效率,ArrayList是没有实现同步(synchronized),如果需要多个
线程并发访问,用户可以手动同步,也可使用Vector替代。
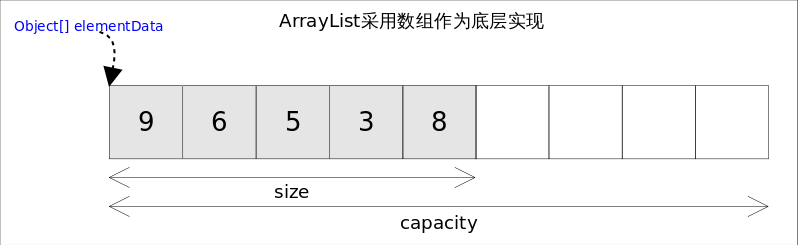
2.每个ArrayList都有一个容量(capacity),表示底层数组的实际大小,容器内存储元素的个数不能多于当前容
量。当向容器中添加元素时,如果容量不足,容器会自动增大底层数组的大小。前面已经提过,Java泛型只是编译
器提供的语法糖,所以这里的数组是一个Object数组,以便能够容纳任何类型的对象。ArrayList容量示意如下:
3. ArrayList继承于AbstractList,实现了List,RandomAccess,Cloneable,java.io.Serializable接口,说明ArrayList提供了随机访问的功能,支持快速访问;覆盖函数clone(),说明能被克隆;还支持序列化。
源码剖析:
1 | // 实现的三个接口说明了 ArrayList 支持随机快速范围、可以被克隆、可序列化。 |
使用场景:
- 经常遍历数据
- 插入顺序与读取顺序相同
- 需要大量随机访问数据
- 极少甚至没有随机插入删除操作形成v
缺陷:
插入效率低。add(index, E) 插入元素,在第几个元素后面插入,后面的元素需要向后移动,时间复杂度O(n)。
根据内容查找元素的效率低,例如
contains(Object o)、indexOf(Object o),时间复杂度O(N)。删除效率低。remove()删除元素,后面的元素需要逐个移动,时间复杂度O(n)。
线程不安全
Vector:
Vector就是ArrayList的线程安全版,它的方法前都加了synchronized锁,其他实现逻辑都相同。当然你也可以手
动写现场安全的ArrayList。如果对线程安全要求不高的话,可以选择ArrayList,毕竟synchronized也很耗性能。
LinkedList:
概述:
故名思意就是链表,和我们大学在数据结构里学的链表是一回事,LinkedList还是一个双向链表。LinkedList同
时实。现了List接口和Deque接口,也就是说它既可以看作一个顺序容器,又可以看作一个队列(Queue),同时
又可以看作一个栈(Stack)。这样看来,LinkedList简直就是个全能冠军。当你需要使用栈或者队列时,可以考虑
使用LinkedList,一方面是因为Java官方已经声明不建议使用Stack类,更遗憾的是,Java里根本没有一个叫
做Queue的类(它是个接口名字)。关于栈或队列,现在的首选是ArrayDeque,它有着比LinkedList*(当作栈或
队列使用时)有着更好的性能。LinkedList的示意图如下图所示。

底层实现:
LinkedList底层*通过双向链表实现*,插入和删除元素时双向链表的维护过程比较重要,也即是直接跟List接口相关的函数。双向链表的每个节点用内部类Node(它的一个内部类)表示。LinkedList通过first和last引用分别指向链表的第一个和最后一个元素。当链表为空的时候first和last都指向null。
源码剖析:
1 | //Node内部类 用于存储元素。和C语言实现方式差不多,由于是双向链表,所以记录了next和prev,只不过把C语言里的指针换成了对象。 |
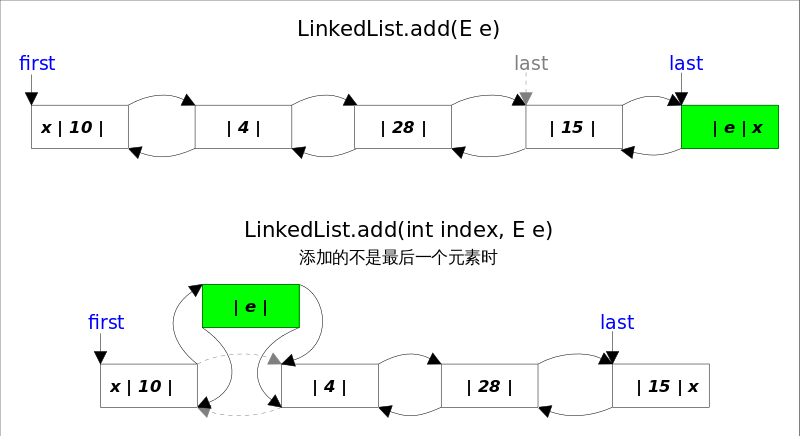
add()方法有两个版本,一个是add(E e),该方法在*LinkedList*的末尾插入元素,因为有last指向链表末尾,在末尾插入元素的花费是常数时间。只需要简单修改几个相关引用即可;另一个是add(int index, E element),该方法是在指定下表处插入元素,需要先通过线性查找找到具体位置,然后修改相关引用完成插入操作。add(int index, E element)的逻辑稍显复杂,可以分成两部分,1.先根据index找到要插入的位置;2.修改引用,完成插入操作。
1 | /** |
remove()方法也有两个版本,一个是删除跟指定元素相等的第一个元素remove(Object o),另一个是删除指定下标处的元素remove(int index)。
两个删除操作都要1.先找到要删除元素的引用,2.修改相关引用,完成删除操作。在寻找被删元素引用的时候remove(Object o)调用的是元素的equals方法,而remove(int index)使用的是下标计数,两种方式都是线性时间复杂度。在步骤2中,两个remove()方法都是通过unlink(Node x)方法完成的。这里需要考虑删除元素是第一个或者最后一个时的边界情况。

1 | /** |
get(int index)得到指定下标处元素的引用,通过调用上文中提到的node(int index)方法实现。
1 | // Positional Access Operations |
set(int index, E element)方法将指定下标处的元素修改成指定值,也是先通过node(int index)找到对应下表元素的引用,然后修改Node中item的值。
1 | /** |
使用场景:
- 如果应用程序有更多的插入或者删除操作,较少的数据读取,LinkedList对象要优于ArrayList对象;
- 不过ArrayList的插入,删除操作也不一定比LinkedList慢,如果在List靠近末尾的地方插入,那么ArrayList只需要移动较少的数据,而LinkedList则需要一直查找到列表尾部,反而耗费较多时间,这时ArrayList就比LinkedList要快。
缺陷:
线程不安全,查找消耗的资源大,效率低,不能随机访问。
三、多线程场景下的使用
通过上面的知识我们可以知道,ArrayList和LinkedList没有实现同步的。那么在多线程的情况,我们怎么使用List呢。有三种思路 分别是:Vector > SynchronizedList > CopyOnWriteArrayList
Vector不过多结束,JDK提供的实现方式,但是不能只能用这一种方案。至少还得说得下面这种:
java.util.Collections.SynchronizedList
它能把所有 List 接口的实现类转换成线程安全的List,比 Vector 有更好的扩展性和兼容性。
很可惜,它所有方法都是带同步对象锁的,和 Vector 一样,它不是性能最优的。即使你能说到这里,面试官还会继续往下追问,比如在读多写少的情况,SynchronizedList这种集合性能非常差,还有没有更合适的方案?
介绍两个并发包里面的并发集合类:
java.util.concurrent.CopyOnWriteArrayList
java.util.concurrent.CopyOnWriteArraySet